NEXON NOW


NEXON NOW is a platform for video games to publish lootbox probabilities to their customers.
It offers the following features:
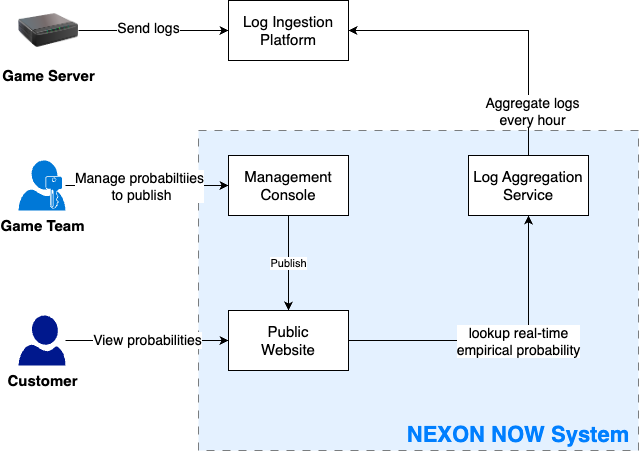
- Hourly aggregation of game server logs to publicly disclose empirical probabilities to customers
- Management of theoretical probabilities through CSV file upload or HTTP request
- Content Management System to organize public webpages showing probabilities to the public
High Level Overview
My Involvement
As the project's starting member, my contribution is 40%.
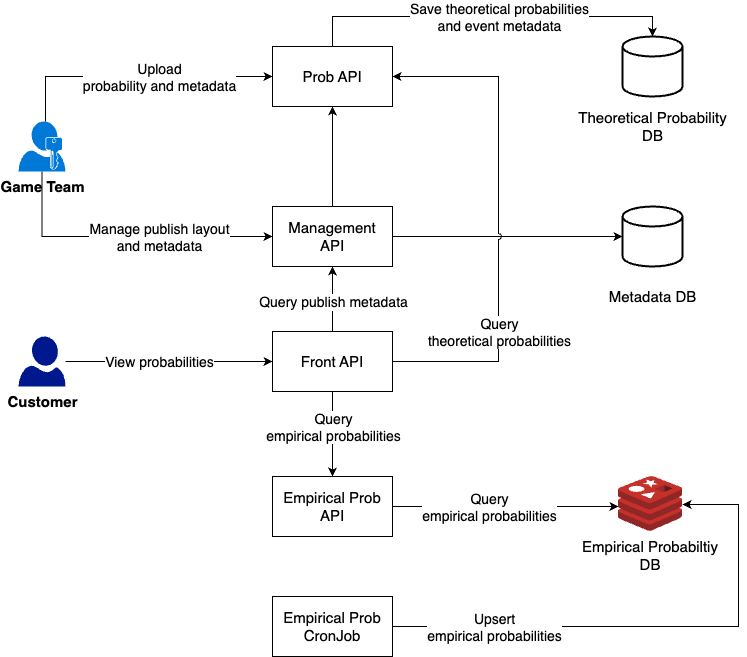
System Design
I have been involved in the project since its inception. Therefore I had a key voice in designing the system.
As part of a team of 4 SWEs, I designed the overall data flow and performed benchmark testing of different query engines and databases for aggregating terabytes of logs per hour. Furthermore, with the team's agreement, the system was split into microservices for compartmentalization and balancing the DB load.
Also, a key challenge was DB Table design that would serve as a common schema for all range of games including but not limited to FPS, RPG, and Racing games.
This required analyzing more than 10 games published by the company and extensive discussions with the game developers.
Challenges
Challenge 1: Aggregating terabytes of logs in under 10 minutes
The cornerstone of this platform lies in its ability to compute empirical probabilities derived from real-time logs. Given that NEXON's portfolio comprises over 50 games, boasting hundreds of millions of global users, the volume of incoming logs is staggering. The challenge was to complete this data processing within a tight 10-minute window to adhere to the platform's hourly probability refresh rate and internal constraints.
Initially, our approach involved channeling all pertinent logs from the internal log ingestion pipeline into a MySQL database, where we executed 'group-by' queries for data aggregation. However, this method proved to be inefficient; both data insertion and query execution were far too slow to meet our time-sensitive requirements. Additionally, any MySQL database failure or maintenance event, such as a version upgrade, posed a substantial risk of disrupting the entire system, unless significant preventive measures were implemented.
To address these challenges, we opted to bifurcate the aggregation process into two discrete steps. The first involves the hourly tallying of individual events, such as the successful enchantment of an item. The second step encompasses the aggregation of these hourly counts over an extended timeframe, ranging from one to several years.
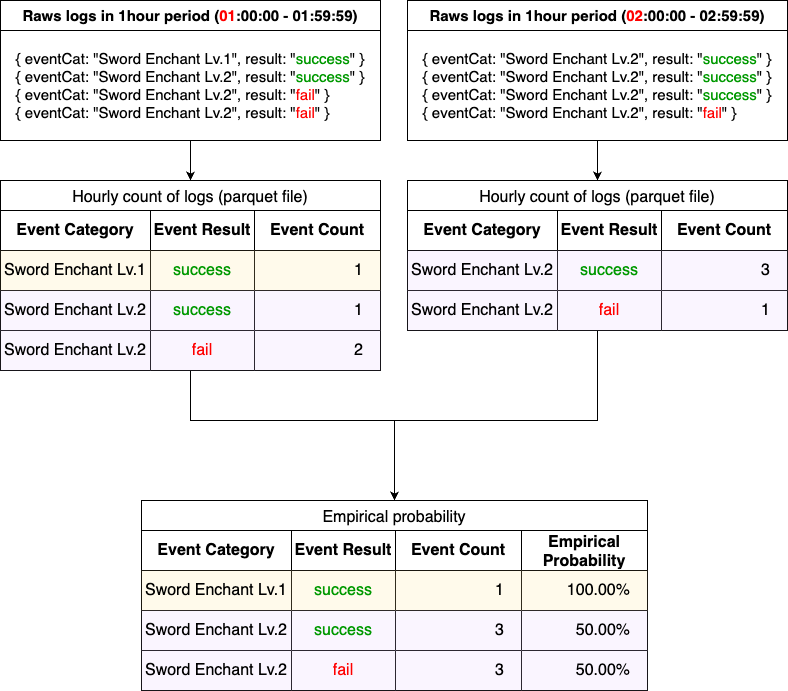
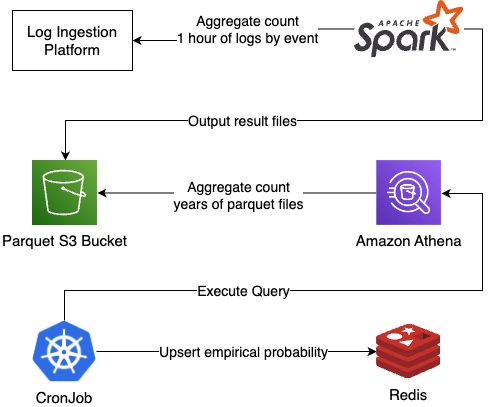
In the revised architecture, the responsibility for hourly event counting was delegated to a Spark cluster, which outputs Parquet files to Amazon S3. A subsequent batch job using Amazon Athena was set up to query these Parquet files. This overhaul yielded several significant advantages:
- Enhanced Availability: Unlike MySQL, the new system eliminated the necessity for manual downtime
- Serverless Architecture: Both scaling and version updates are autonomously managed, minimizing operational overhead
- Cost Efficiency: Utilizing S3 and Athena led to cost reductions of up to 90% compared to maintaining a large MySQL cluster
- Version Control: S3 offers native versioning, a feature that would require manual implementation in MySQL
- Concurrency Support: S3 file uploads do not block Athena queries, solving the table-locking issues we had with MySQL
Our testing showed even the biggest Athena queries finishing in under 3 minutes. These queries scanned parquet files for over 3 years with more than 70K unique rows.
Despite these benefits, the new system presented some challenges. Athena queries are asynchronous and could be influenced by the activities of other accounts using Athena in the same region. The QueryExecutionStatus transitions through a sequence of states—QUEUED, RUNNING, SUCCEEDED/FAILED/CANCELED—that require manual monitoring. To address this, we employed Kotlin Coroutines' IO tasks to execute queries concurrently while synchronously waiting for and checking these status updates.
Another hurdle was related to storing the Athena query results. Given the frequency of empirical probability lookup operations, S3 was deemed unsuitable. Initially, MySQL was considered, but we ran into performance bottlenecks and deadlock issues. We eventually selected Redis as our primary database for storing calculated empirical probabilities. Despite initial concerns about Redis' volatility, its features swayed our decision:
- Data Redundancy: Replication across multiple availability zones considerably reduces the risk of data loss.
- Data Recalculability: Empirical probabilities, which are valid for just one hour, can be recalculated using the stored Parquet files in S3.
- High-Performance Bulk Upsert: Redis demonstrated a marked improvement over MySQL in bulk upsert operations when using pipelining.
Challenge 2: Managing Sudden Spikes in Web Traffic
NEXON NOW's web traffic generally follows a predictable pattern, exhibiting gradual increases and decreases. Utilizing Kubernetes' Horizontal Pod Autoscaler (HPA) and Cluster Autoscaler (CA), we successfully managed regular traffic fluctuations without requiring manual intervention.
However, the system faced difficulties in accommodating abrupt spikes in traffic, particularly during major events like game launches or the completion of game maintenance. These spikes resulted in a surge of incoming requests, leading to 500 errors for end-users. To address this, we implemented two significant changes:
Change 1: Transition to a Reactive Web Server
Our initial server architecture was built on Spring Web MVC, utilizing Tomcat as its Web Application Server. Tomcat employs a thread-based, synchronous model for handling web requests. We observed that reactive servers exhibited greater efficiency in managing high volumes of requests. Consequently, we migrated to Spring WebFlux, which employs Netty as its underlying engine.
The transition from a synchronous to a reactive codebase posed challenges, particularly as our data source drivers were synchronous. Moreover, a stable version of a reactive driver for MySQL was unavailable. However, we found a stable reactive driver for Redis and optimized our caching strategies. As a result, 99% of the requests were served reactively via the Redis cache. This major overhaul led to a 34% increase in request throughput per pod.
Change 2: Implementation of Circuit Breakers
Although our refactored reactive server effectively managed spiky traffic, we sought additional layers of resilience. Implementing circuit breakers in the Front API allowed us to prepare for potential system failures. If Redis were to fail entirely, the circuit breakers facilitate rapid failover to MySQL, while also limiting the number of concurrent requests through the use of a Bulkhead mechanism.
Outcomes
- Enabled 15+ games (aggregate revenue $1.4B) to meet regulatory requirements for disclosing loot box probability
- Refactored internet-facing servers to reactive Spring WebFlux and Kotlin coroutines, increasing request throughput by up to 34%
- Optimized ETL pipeline to reduce estimated AWS spending by up to 90%
Description
NEXON NOW is a probability disclosure platform for online video games. It is used by 15+ games to transparently disclose near real-time loot box probabilities to customers.